SciDef: Automating Definition Extraction from Academic Literature with Large Language Models
Highlights
- SciDef automates definition extraction from academic literature with large language models.
- The pipeline compares one-step, multi-step, and DSPy-optimized prompting strategies.
- DefExtra contributes 268 human-extracted definitions from 75 papers across media bias and out-of-domain sources.
- DefSim adds human labels for definition similarity and paper-level extraction quality.
- NLI-based similarity provides the most reliable evaluation signal for matching extracted definitions.
- The public DefExtra release ships markers only and can be hydrated with your own PDFs.
Figures
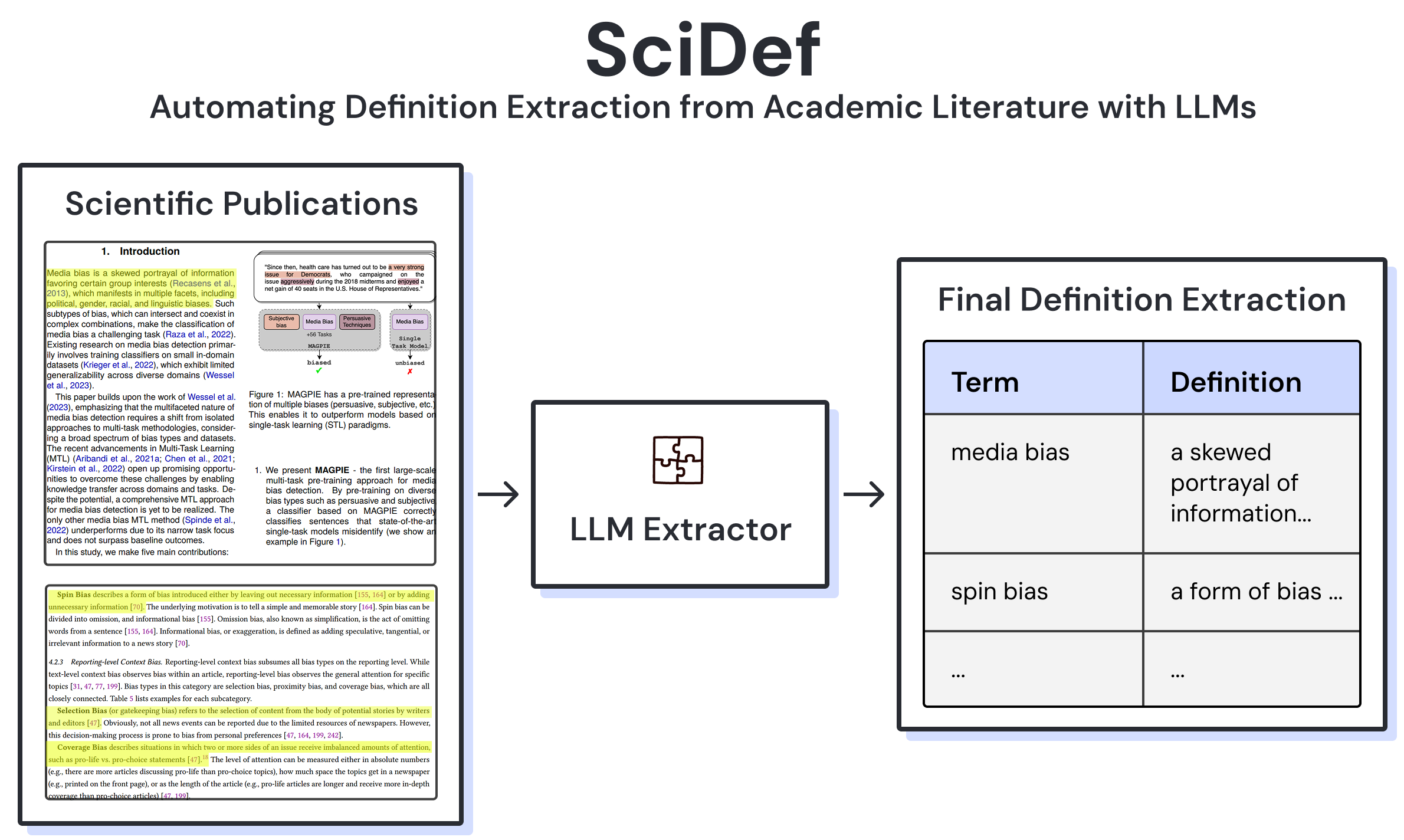
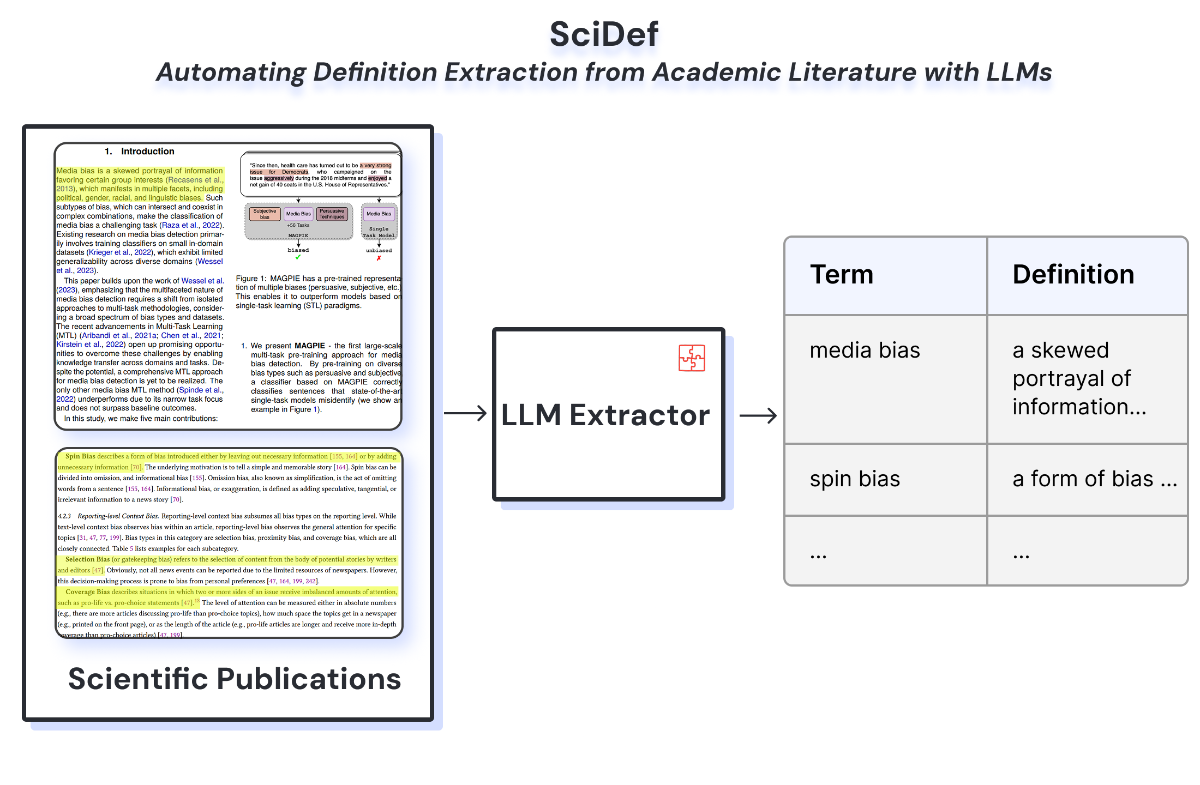
Overview poster of the SciDef task, datasets, and evaluation setup.
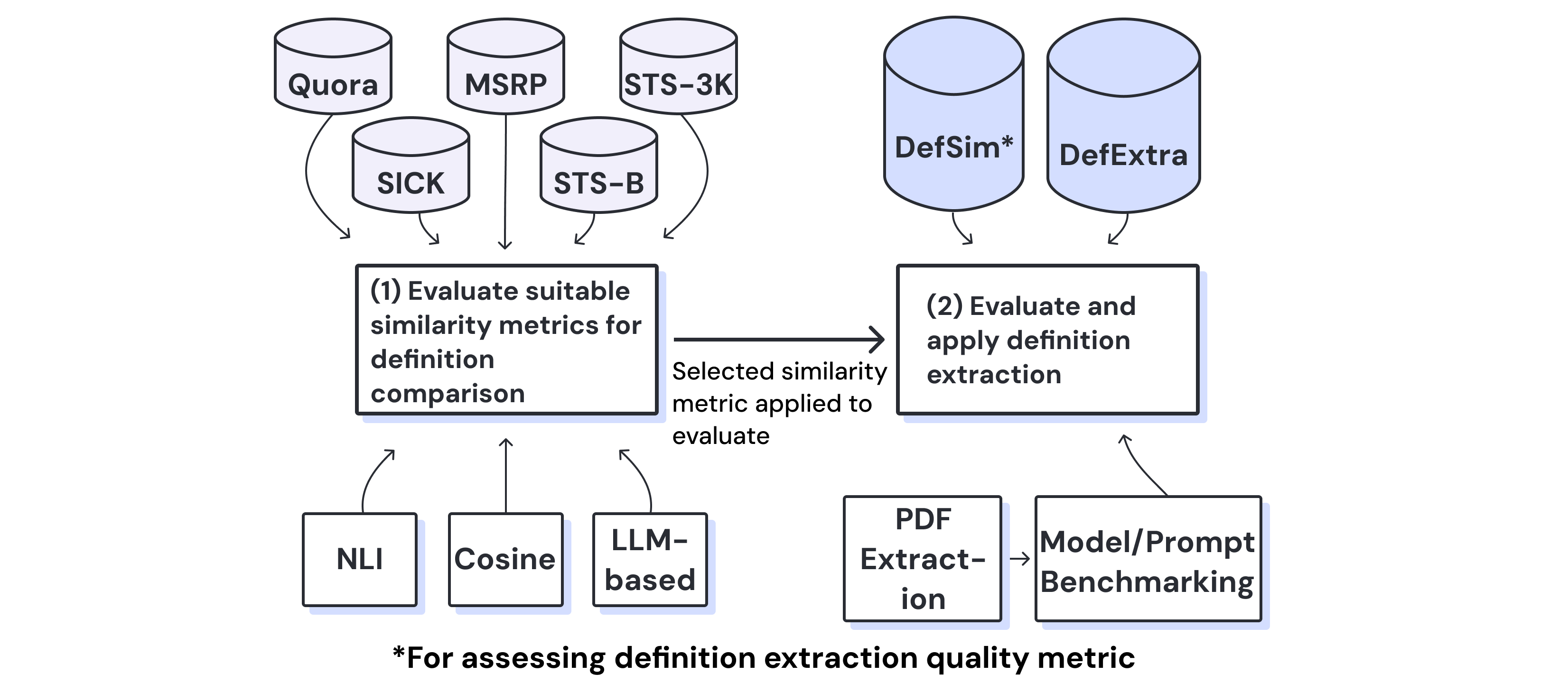
SciDef workflow from keyword selection through extraction and evaluation.
Abstract
Definitions are the foundation for any scientific work, but with the significant increase in publication numbers, gathering definitions relevant to any keyword has become increasingly challenging. We therefore introduce SciDef, an LLM-based pipeline and resource for automated definition extraction. We test SciDef on DefExtra and DefSim, specifically created datasets of human-extracted definitions and human-labeled definition similarity, respectively. Evaluating multiple language models across prompting strategies and similarity metrics, we show that multi-step and DSPy-optimized prompting improve extraction performance and that NLI-based similarity yields the most reliable evaluation.
BibTeX
@misc{kucera2026scidefautomatingdefinitionextraction,
title={SciDef: Automating Definition Extraction from Academic Literature with Large Language Models},
author={Filip Ku\v{c}era and Christoph Mandl and Isao Echizen and Radu Timofte and Timo Spinde},
year={2026},
eprint={2602.05413},
archivePrefix={arXiv},
primaryClass={cs.IR},
url={https://arxiv.org/abs/2602.05413},
}